
缘起
我在多年前上机器学习的课时,使用过TensorFlow,但是当时对深度学习的理解还不够深入,只是简单地使用了一下。后来我也再没有上过机器学习的课,但研究工作中还是用到了一些机器学习的知识,所以我断断续续地学习了一些机器学习的知识。
现在深度学习已经成为机器学习的主流方法,而PyTorch是一个非常流行的深度学习框架。我之前也了解过PyTorch,但是没有系统地学习过,所以我最近决定系统地学习一下PyTorch。
尽管网上已经有很多关于PyTorch的教程了,但是我还是想自己再开一个系列“实例学PyTorch”,主要是为了加深自己的理解。这个系列的目标是从PyTorch的基础开始,用PyTorch官方给的实例,来学习用PyTorch实现一些经典的机器学习模型。
PyTorch官方给了很多实例,包括MNIST手写数字识别、CIFAR-10图像分类、IMDB情感分析等,GitHub仓库地址是https://github.com/pytorch/examples。这些实例都是深度学习的Hello World,非常适合初学者学习。但是PyTorch官方基本只给了代码,没有讲解,对于初学者来说可能不够友好。所以我打算用这个系列来讲解这些实例,希望能帮助初学者更好地学习PyTorch。
这里我重新建了一个GitHub仓库,其主体是PyTorch官方的示例,但是我会给每个示例添加一些辅助性的代码和文档,方便初学者学习。这个仓库的地址是https://github.com/jin-li/pytorch-tutorial,欢迎大家Star和Fork。
PyTorch基础
![]()
PyTorch简介
PyTorch是一个开源的深度学习框架,由Facebook的人工智能研究团队开发。PyTorch提供了两个主要的功能:
- 一个多维张量库,类似于NumPy,但是可以在GPU上运行。
- 一个自动微分引擎,用于构建和训练神经网络。
PyTorch的优点:
- PyTorch是一个动态图框架,可以更灵活地定义神经网络。
- PyTorch的API更加Pythonic,更容易学习和使用。
- PyTorch的社区更加活跃,有更多的教程和示例。
PyTorch运行环境
PyTorch支持多种操作系统,包括Linux、Windows和macOS。PyTorch支持多种硬件设备,包括CPU、GPU和TPU。PyTorch支持多种编程语言,包括Python、C++和Java。
这里我本人的运行环境是一台装有Ubuntu 22.04的台式机,配备了Intel Core i5-9600K处理器和NVIDIA GeForce GTX 4060 Ti显卡。CPU内存为64GB,GPU内存为8GB。但本系列教程中,我会尽量既使用CPU,又使用GPU,既作为性能对比,又方便读者可以在不同的硬件设备上运行。
PyTorch安装
PyTorch的安装非常简单,只需要使用pip命令即可。但如果直接用pip安装,可能会弄乱自己的Python环境,所以我们每次都会使用conda创建一个虚拟环境,然后在虚拟环境中运行PyTorch实例。
关于Python环境的管理,我之前写过一篇文章“Python环境管理方式总结”,有兴趣的读者可以参考。
MNIST手写数字识别
MNIST是一个非常经典的手写数字识别数据集,包含了60000张训练图片和10000张测试图片。每张图片都是28x28像素的灰度图像,标签是0到9之间的一个数字。MNIST已经成为了深度学习,尤其是计算机视觉(Computer Vision, CV)领域的Hello World,几乎所有的深度学习框架都有MNIST的示例。这里我们就从MNIST开始,来开启我们的PyTorch学习之旅。
流程概述
使用PyTorch实现深度学习模型的一般流程如下:
- 准备数据集:下载数据集,将数据集转换为PyTorch的数据集。
- 定义模型:定义神经网络模型,包括网络结构和参数。
- 训练模型:使用训练数据集训练模型,调整模型参数。
- 测试模型:使用测试数据集测试模型,评估模型性能。
这里我们就按照这个流程来实现MNIST手写数字识别。
准备数据集
对于MNIST手写数字识别问题,数据集的准备很简单,因为PyTorch已经内置了MNIST数据集。我们只需要使用torchvision.datasets.MNIST类即可,这里我们可以指定train=True表示训练数据集,train=False表示测试数据集。
|
|
MNIST数据集是一系列的图片和标签,每张图片是一个28x28的灰度图像,每个标签是一个0到9之间的数字。

这里我们在用datasets.MNIST()拿到数据集之后,又使用torch.utils.data.DataLoader()将数据集转换为PyTorch的数据集。DataLoader是一个迭代器,可以方便地对数据集进行批处理,这里我们指定batch_size=64表示每次取64个样本,shuffle=True表示每次取样本时打乱顺序。
定义模型
这里我们选择使用神经网络来实现手写数字识别。确定了模型的类型之后,我们需要考虑模型的具体结构,包括网络的层数、每层的神经元数、激活函数等。这些参数的选择跟具体的问题有关,并且非常依赖于经验。
-
我们可以先确定输入和输出。显然这个神经网络的输入是28x28的灰度图像,输出是0到9之间的一个数字。
-
我们需要选择一个神经网络类型,例如全连接神经网络、卷积神经网络、循环神经网络等。这里我们选择使用全连接神经网络。
-
我们需要确定网络的结构,包括网络的层数、每层的神经元数、激活函数等。这里我们选择一个简单的神经网络,包括一个输入层、一个隐藏层和一个输出层。
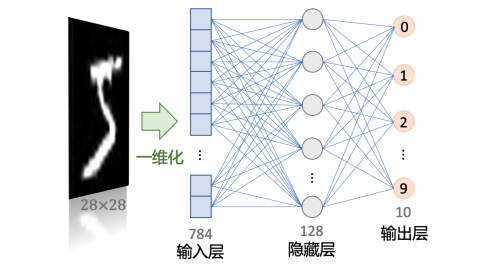
创建这个神经网络的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15import torch import torch.nn as nn import torch.nn.functional as F class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(28 * 28, 128) # Input layer to hidden layer self.fc2 = nn.Linear(128, 10) # Hidden layer to output layer def forward(self, x): x = x.view(-1, 28 * 28) # Flatten the input image x = F.relu(self.fc1(x)) # Apply ReLU activation x = self.fc2(x) # Output layer return F.log_softmax(x, dim=1) # Apply log-softmax for classification这里我们定义了一个名为
Simple的类,继承自nn.Module。在PyTorch中,所有的神经网络模型都需要继承自nn.Module类,并实现__init__和forward方法。- 在
__init__方法中,我们定义了两个全连接层fc1和fc2,分别表示输入层到隐藏层和隐藏层到输出层。nn.Linear表示全连接层,第一个参数表示输入神经元数,第二个参数表示输出神经元数。 - 在
forward方法中,我们定义了网络的前向传播过程,即输入数据经过每一层的计算,最后输出预测结果。其中:x.view(-1, 28 * 28)表示将输入数据展平为一维向量,即将28x28的图像展平为784维向量。F.relu(self.fc1(x))表示将输入数据输入到第一个全连接层中,然后应用ReLU激活函数。self.fc2(x)表示将ReLU激活后的数据输入到第二个全连接层中,得到输出结果。F.log_softmax(x, dim=1)表示将输出结果转换为概率,即对每个类别的输出取对数概率。
- 在
训练模型
有了数据集和模型之后,我们就可以开始训练模型了。训练模型的原理是通过梯度下降算法,不断调整模型参数,使得模型的预测结果和真实结果之间的误差最小。
训练模型的一般流程如下:
- 初始化模型参数。
- 从数据集中取出一个批次的数据。
- 将数据输入到模型中,得到模型的预测结果。
- 计算模型的预测结果和真实结果之间的误差。
- 使用梯度下降算法更新模型参数。
- 重复步骤2到步骤5,直到模型收敛。
其中最为关键的是第4步和第5步,即计算误差和更新参数。PyTorch提供了torch.optim模块来实现梯度下降算法,提供了torch.nn.functional模块来实现损失函数。更新参数的过程是通过反向传播算法实现的,PyTorch提供了loss.backward()方法来计算梯度,提供了optimizer.step()方法来更新参数。
损失函数和反向传播算法是深度学习的核心,因为损失函数决定了模型的优化目标,反向传播算法决定了如何调整模型参数。
损失函数
损失函数是用来衡量模型的预测结果和真实结果之间的差异,即模型的误差。PyTorch提供了很多常用的损失函数:
- 分类问题:交叉熵损失函数
torch.nn.CrossEntropyLoss(),负对数似然损失函数torch.nn.NLLLoss()等。 - 回归问题:均方误差损失函数
torch.nn.MSELoss()。 - 二分类问题:二元交叉熵损失函数
torch.nn.BCELoss()。 - 多标签分类问题:多标签交叉熵损失函数
torch.nn.BCEWithLogitsLoss()。
反向传播
反向传播算法是用来计算模型参数的梯度,即模型的误差对参数的导数。PyTorch提供了loss.backward()方法来计算梯度,然后使用optimizer.step()方法来更新参数。
训练代码
我们把这个过程封装成一个train函数:
|
|
model.train()表示将模型设置为训练模式,这样模型中的Dropout层和BatchNorm层会起作用。optimizer.zero_grad()表示将优化器的梯度清零,因为PyTorch默认会累积梯度。output = model(data)表示将数据输入到模型中,得到模型的预测结果。loss = F.nll_loss(output, target)表示计算模型的预测结果和真实结果之间的误差,这里使用负对数似然损失函数。loss.backward()表示使用反向传播算法计算模型参数的梯度。optimizer.step()表示使用梯度下降算法更新模型参数。
注意,由于我们事先把数据集转换为PyTorch的数据集,所以每次取出的数据是一个批次的数据,即data是一个张量,对MNIST数据集来说,data的形状是(batch_size, 1, 28, 28),target的形状是(batch_size,)。
训练完所有的数据被称为完成一个epoch,我们可以多次迭代训练数据集。但需要注意的是,训练数据集的多次迭代并不一定能提高模型的性能,因为可能会导致过拟合。因此我们需要在训练过程中监控模型的性能,及时停止训练。
为什么在训练时我们要分批次训练呢?因为一次性训练所有数据可能会导致内存不足,而且分批次训练可以加速训练过程。
分批次为什么能加速训练呢?因为分批次训练可以利用矩阵乘法的并行性,同时计算多个样本的预测结果和误差,从而加速计算。
如何选择批次大小呢?批次大小的选择是一个超参数,需要根据具体的问题和硬件设备来选择。一般来说,批次大小越大,训练速度越快,但是内存消耗也越大。批次大小的选择也会影响模型的收敛速度和泛化能力。
测试模型
训练模型之后,我们需要测试模型的性能。测试模型的一般流程如下:
- 从测试数据集中取出一个批次的数据。
- 将数据输入到模型中,得到模型的预测结果。
- 计算模型的预测结果和真实结果之间的误差。
- 重复步骤1到步骤3,直到测试数据集遍历完毕。
|
|
model.eval()表示将模型设置为评估模式,这样模型中的Dropout层和BatchNorm层不会起作用。with torch.no_grad():表示不需要计算梯度,因为在测试阶段我们只需要计算模型的预测结果,不需要更新模型参数。- 这里的误差是整个测试数据集的平均误差。
pred = output.argmax(dim=1, keepdim=True)表示取出预测结果中概率最大的那个类别。correct += pred.eq(target.view_as(pred)).sum().item()表示计算预测正确的样本数。
主程序
有了上面的准备工作,我们就可以开始训练和测试模型了。这里我们定义一个main函数,用来调用train和test函数。
|
|
-
transforms.Compose()表示将多个数据转换操作组合在一起。 -
transforms.ToTensor()表示将数据转换为张量。 -
transforms.Normalize()表示对数据进行标准化,即减去均值除以标准差。这里的均值和标准差是MNIST数据集的均值和标准差,可以通过计算得到,具体代码如下:1 2 3 4 5 6 7 8 9 10 11 12 13import torch from torchvision import datasets, transforms # Load the MNIST dataset without any transformations dataset = datasets.MNIST('../data', train=True, download=True, transform=transforms.ToTensor()) # Compute the mean and standard deviation loader = torch.utils.data.DataLoader(dataset, batch_size=60000, shuffle=False) data = next(iter(loader))[0] # Get all the images in a single batch mean = data.mean().item() std = data.std().item() print(f'Mean: {mean}, Std: {std}')我把这段代码放在了
get_mnist_statistics.py文件中,可以直接运行。 -
model = SimpleNN().to(device)表示将模型移动到指定的设备上,这里我们可以指定CPU或GPU。
完整代码
上面就是实现MNIST手写数字识别所需要的全部主要代码,我把这些代码整合到了一个文件mnist_nn.py中。上面提到的所有代码参见我的GitHub仓库https://github.com/jin-li/pytorch-tutorial中的T01_mnist_nn文件夹。
除了上面的代码,我还仿照PyTorch官方的示例,定义了一些解析命令行参数的代码,这样我们可以通过命令行来指定一些参数,例如学习率、批次大小、迭代次数等。输入下面的命令,可以查看所有的参数:
|
|
Python环境
在运行代码之前,我们需要创建一个Python虚拟环境,并安装PyTorch和其他依赖包。Python的环境管理工具有很多,可参见我之前写的文章“Python环境管理方式总结”。这里我使用conda来创建一个给本系列教程用的虚拟环境,并安装PyTorch和其他依赖包。
|
|
运行代码
我们运行这个代码,可以看到模型在测试数据集上的性能:
|
|
上面的代码默认使用GPU来运行,在我的机器上(NVIDIA GeForce GTX 4060 Ti)需要2分15秒左右。如果没有GPU,可以指定--no-cuda参数只使用CPU,在我的机器上(Intel Core i5-9600K)需要3分1秒左右,比使用GPU略慢,但没有慢很多,这是因为我们的模型比较简单,而且MNIST数据集也比较小。
在运行14个epoch之后,可以得到如下的输出:
|
|
即我们这个简单的三层神经网络模型在MNIST数据集上的准确率为98%,这个效果已经非常不错了。
总结
在本篇文章中,我们介绍了PyTorch的基本概念和使用方法,然后使用一个简单的三层全连接神经网络实现了MNIST手写数字识别。这算是深度学习领域的“Hello World"。然而,这个神经网络中的参数都是直接给出的,我们并没有讨论这些参数是怎么来的,也没有讨论这些参数的选择对模型性能的影响。在下一篇文章中,我们将尝试不同的参数选择对模型性能的影响,以及如何调整这些参数来提高模型的性能。